OpenAI开发系列(二) 大语言模型发展史与Transformer架构详解
随着人工智能技术的飞速发展,大语言模型已成为推动自然语言处理领域的核心驱动力。本文将从计算机软硬件开发及销售的角度,系统梳理大语言模型的发展历程,并深入解析作为其基石的Transformer架构。
一、大语言模型发展史:从理论到商业化的演进
大语言模型的发展,离不开计算机软硬件技术的持续迭代与商业化应用。其演进路径可概括为三个阶段:
- 早期探索与统计模型阶段(20世纪90年代-2010年代):此阶段的模型以统计方法为主,如N-gram模型和隐马尔可夫模型。这些模型受限于计算能力和数据规模,通常依赖于特定领域的小规模数据,且商业化应用集中在语音识别、基础文本分类等有限场景。硬件以CPU为主流,软件实现相对简单。
- 深度学习与神经网络兴起阶段(2010年代-2017年):随着GPU在并行计算上的优势被发掘,以及深度学习框架(如TensorFlow、PyTorch)的成熟,神经网络模型开始主导。基于循环神经网络(RNN)和长短时记忆网络(LSTM)的序列模型得到广泛应用,推动了机器翻译、情感分析等商业化产品的落地。RNN系列模型存在训练效率低、长程依赖处理能力弱等瓶颈。
- Transformer时代与大模型商业化爆发(2017年至今):2017年,Google在论文《Attention Is All You Need》中提出Transformer架构,彻底改变了自然语言处理的范式。OpenAI、Google、Meta等机构基于Transformer相继推出GPT系列、BERT、T5等大语言模型。这些模型参数规模从数亿扩展到数千亿,依赖高性能GPU集群(如NVIDIA A100/H100)和分布式训练框架进行开发。在销售与应用层面,大语言模型通过API服务(如OpenAI的GPT API)、云平台集成和行业解决方案等形式,广泛赋能搜索引擎、智能客服、内容生成、代码辅助等商业场景,形成了从硬件(专用AI芯片、服务器)到软件(预训练模型、微调工具)再到服务(SaaS、定制化开发)的完整产业链。
二、Transformer架构详解:驱动大语言模型的核心引擎
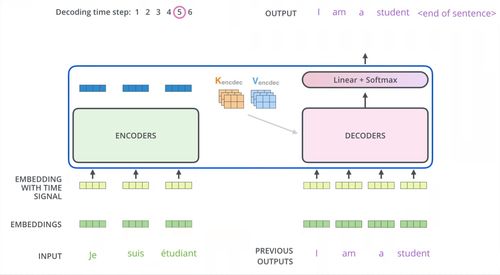
Transformer是一种完全基于自注意力机制的神经网络架构,其设计兼顾了高效并行计算与强大的序列建模能力,成为当前大语言模型的标配。下面从计算机实现的角度解析其核心组件:
- 自注意力机制(Self-Attention):这是Transformer的核心创新。通过计算输入序列中每个词与其他词的相关性权重,模型能够动态捕捉长距离依赖关系。从硬件角度看,自注意力的大规模矩阵运算非常契合GPU的并行计算特性,显著提升了训练和推理效率。软件实现上,通常采用优化后的矩阵库(如CUDA加速)来保证计算速度。
- 编码器-解码器结构:原始Transformer包含编码器和解码器堆栈。编码器用于理解输入序列,解码器用于生成输出序列。在如BERT等模型中仅使用编码器,而GPT系列仅使用解码器。这种模块化设计便于软件层面的灵活调整与复用,支持不同任务(如理解vs.生成)的模型开发。
- 位置编码(Positional Encoding):由于Transformer本身不具备序列顺序信息,需要通过位置编码为输入添加位置信息。常见方式包括正弦余弦编码或可学习的位置嵌入。这一机制在软件实现上简单高效,无需如RNN那样的递归计算。
- 前馈神经网络与残差连接:每个注意力层后接一个前馈网络,并采用残差连接和层归一化来稳定深度网络的训练。这有助于缓解梯度消失问题,使得训练超深层模型(如GPT-3的1750亿参数)成为可能,这对硬件(大内存、高带宽)和软件(梯度优化、分布式训练)提出了极高要求。
- 规模化与硬件协同:Transformer架构的扩展性极强,模型性能随参数规模和数据量增加而显著提升。这驱动了专用AI硬件(如TPU、AI加速卡)的研发与销售,以及配套软件栈(如DeepSpeed、Megatron-LM)的优化,以降低大规模训练的复杂度和成本。
大语言模型的发展史,本质上是算法创新、计算硬件升级与商业化探索交织的历程。Transformer架构以其卓越的并行能力和扩展性,成为这一进程的关键转折点。对于从事计算机软硬件开发及销售的企业与开发者而言,深入理解Transformer的原理及其在硬件加速、软件框架和云端服务中的应用,是把握AI时代商业机遇的重要基础。随着模型压缩、边缘计算等技术的发展,大语言模型有望进一步向低成本、高能效的方向演进,开拓更广阔的软硬件市场空间。
如若转载,请注明出处:http://www.hangrentec.com/product/62.html
更新时间:2026-06-19 07:08:37